Open-source · DGX Spark · GB10
What actually runs on a DGX Spark.
SparkBench is a community lab for the NVIDIA GB10. We benchmark every model on real hardware, publish reproducible recipes for coding, agents, and reasoning, and ship the tooling so you can run it on your own box.
18
Models benched
75.8 t/s @ 40k
Peak throughput
3
Inference engines
1
GB10 box
Leaderboard
Rankings are by throughput (tok/s) on a single GB10
— not by intelligence, coding quality, or SWE benchmarks.
We can't wait to add those. Contributions welcome ↗
| # | Model | For | Engine | Params | Throughput | |
|---|---|---|---|---|---|---|
| 01 | Qwen3-30B-A3B nvidia/qwen3-30b-a3b | AgentsGeneralReasoning | vLLM | — |
75.8t/s@ 40k
|
HF ↗ |
| 02 | Qwen3.6-35B-A3B (NVFP4) nvidia/qwen3.6-35b-a3b | AgentsGeneralReasoning | vLLM | — |
73.5t/s@ 64k
|
HF ↗ |
| 03 | Qwen3-Coder-30B-A3B-Instruct unsloth/qwen3-coder-30b-a3b-instruct | AgentsCode | llama.cpp | — |
70.9t/s@ 32k
|
HF ↗ |
| 04 | Diffusiongemma 26B A4B It google/diffusiongemma-26b-a4b-it | MultimodalReasoning | vLLM | — |
70.8t/s@ 16k
|
HF ↗ |
| 05 | qwen3-coder-next saricles/qwen3-coder-next | AgentsCode | vLLM | — |
63.3t/s@ 256k
|
private |
| 06 | Qwen3.6-35B-A3B (GGUF) unsloth/qwen3.6-35b-a3b | AgentsGeneralReasoning | llama.cpp | — |
48.6t/s@ 32k
|
HF ↗ |
| 07 | qwen3-coder-next qwen/qwen3-coder-next | AgentsCode | vLLM | — |
45.4t/s@ 256k
|
HF ↗ |
| 08 | Qwen3.6-27B (FP8) qwen/qwen3.6-27b | AgentsGeneralReasoning | vLLM | 27B |
27.5t/s@ 256k
|
HF ↗ |
| 09 | Gemma-4-26B-A4B-IT google/gemma-4-26b-a4b-it | GeneralMultimodalReasoning | vLLM | — |
23.6t/s@ 8k
|
HF ↗ |
| 10 | Step-3.7-Flash stepfun-ai/step-3.7-flash | AgentsMultimodal | llama.cpp | 198B |
22.3t/s@ 32k
|
HF ↗ |
| 11 | Gemma-4-12B-IT google/gemma-4-12b-it | GeneralMultimodal | llama.cpp | — |
21.1t/s@ 32k
|
HF ↗ |
| 12 | gemma-4-12b-coder-fable5-composer2.5-v1 yuxinlu1/gemma-4-12b-coder-fable5-composer2.5-v1 | Code | llama.cpp | — |
18.6t/s@ 32k
|
HF ↗ |
| 13 | Qwen3.6-27B (PrismaQuant) rdtand/qwen3.6-27b | GeneralReasoning | vLLM | 27B |
10.3t/s@ 16k
|
HF ↗ |
| 14 | Qwen3.6-27B (unsloth) unsloth/qwen3.6-27b | AgentsGeneralReasoning | vLLM | 27B |
9.4t/s@ 64k
|
HF ↗ |
| 15 | Qwen3.6-27B (MoQ GGUF) kaitchup/qwen3.6-27b | GeneralReasoning | llama.cpp | 27B |
9.3t/s@ 32k
|
HF ↗ |
| 16 | Phi-4 microsoft/phi-4 | GeneralReasoning | vLLM | — |
8.0t/s@ 16k
|
HF ↗ |
| 17 | Hermes-4-14B nousresearch/hermes-4-14b | AgentsReasoning | vLLM | — |
8.0t/s@ 40k
|
HF ↗ |
| 18 | DeepSeek-R1-Distill-Qwen-32B deepseek-ai/deepseek-r1-distill-qwen-32b | Reasoning | vLLM | — |
3.6t/s@ 128k
|
HF ↗ |
Recipes by task
General
Agents
Reasoning
Code
Run it on your own Spark
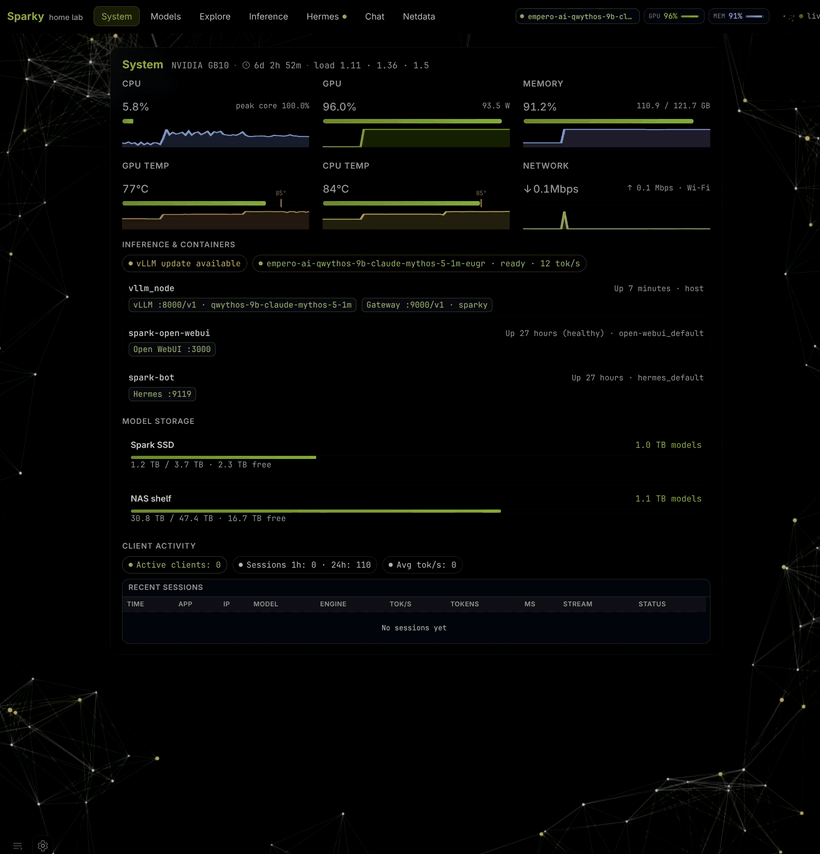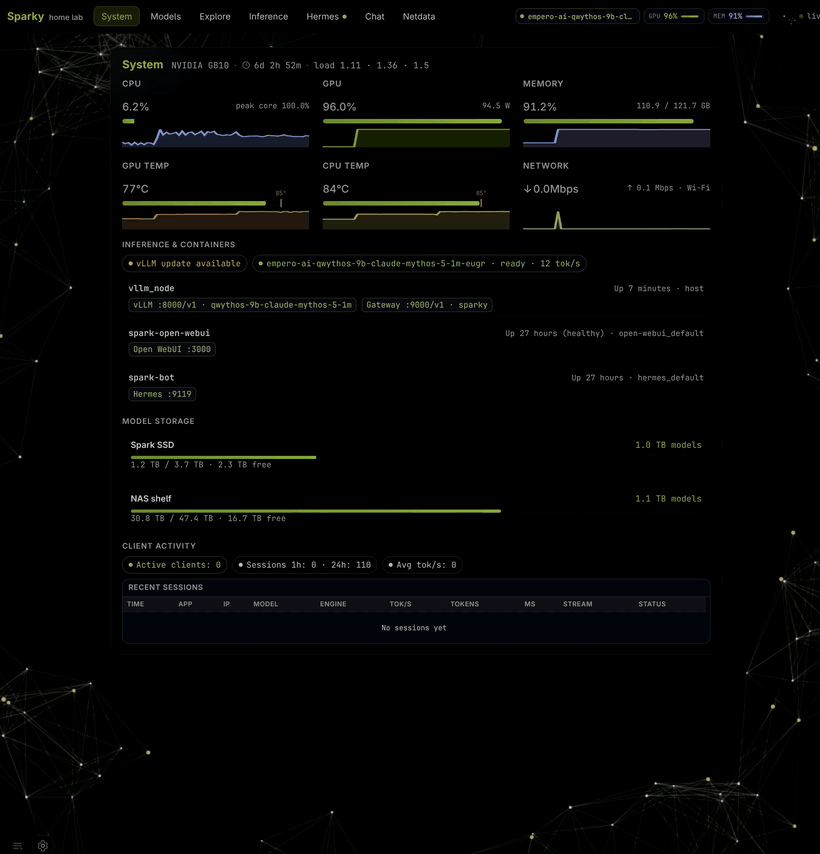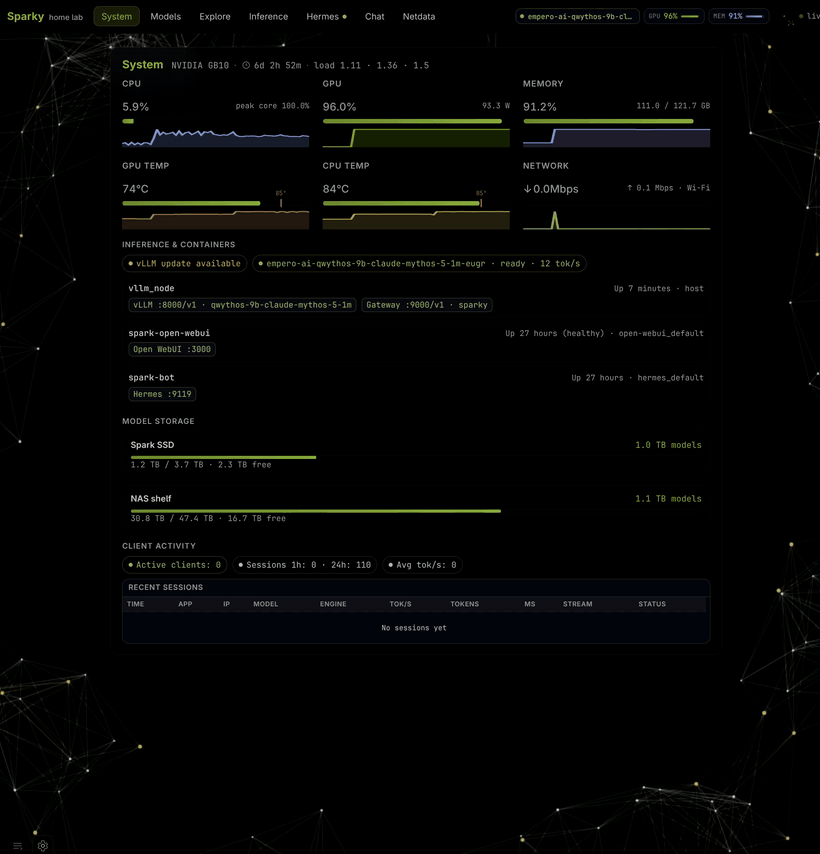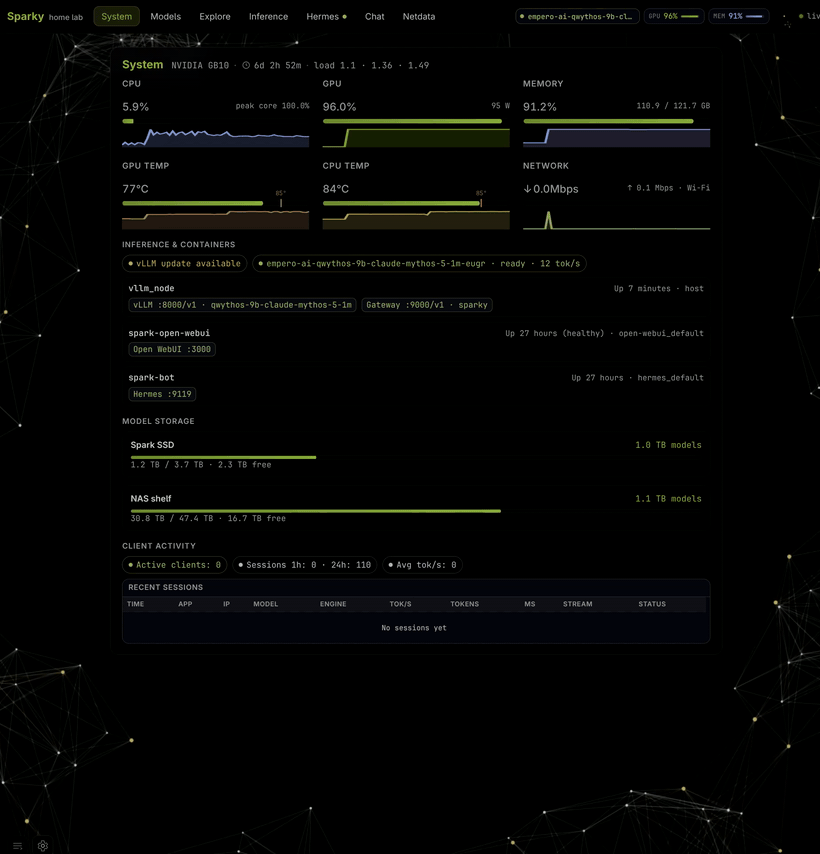
SparkBench is the operator tool behind this site. Portal, model inventory, three inference engines (vLLM, llama.cpp, ds4), reproducible bench v2, and an OpenAI gateway — one CLI on your GB10.
- One bootstrap command — clone, host env, portal, APIs, CLI.
- Three engines — eugr, llama.cpp, ds4. One GPU at a time.
- Real recipes — auto-scaffolded from weights; golden map in git.
- Your data, your box — nothing leaves the LAN unless you ship it here.
install
shell
# One command — core stack (no GPU engine yet) curl -fsSL https://raw.githubusercontent.com/shawnmarck/sparkbench/main/scripts/bootstrap-sparkbench.sh | sudo bash # Then pick an engine + gateway sudo bash install/spark-install engine eugr sudo bash install/spark-install gateway # Switch, bench, serve spark inference list spark inference up qwen36-nvfp4 spark inference bench